MySQL SQL Notes - Part 5 (Optimization - Engines, Database Replication, Character Set, Collation )
Alternative Storage Engines
In MySQL, a storage engine is a software component responsible for managing the storage of data in database tables. MySQL provides support for various storage engines, each with its own features and performance characteristics. Each storage engine implements its own set of rules and algorithms for storing, retrieving, and manipulating data.
Sometimes out queries may run slower on some engines but faster on a different engine, so we can optimize SQL queries by testing performance on multiple engines and choose the one best for the operation
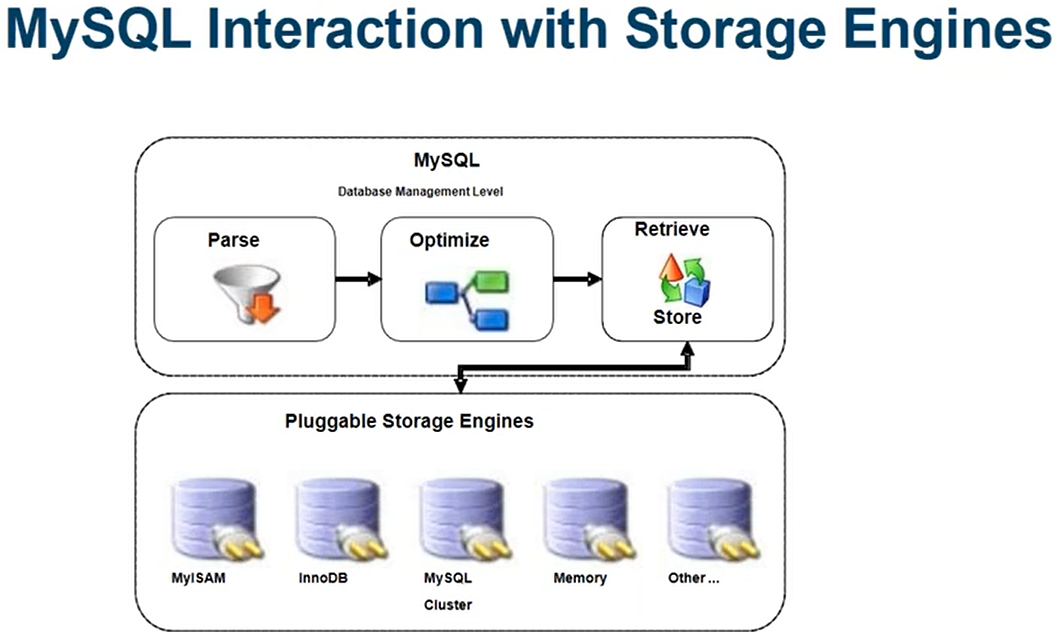
Below are some commonly used storage engines in MySQL as followed :
InnoDB:
- InnoDB is the default storage engine in MySQL from version 5.5 onwards.
- It provides support for transactions (ACID-compliant), foreign keys, and row-level locking.
- InnoDB is well-suited for OLTP (Online Transaction Processing) workloads where there are frequent read and write operations.
- Suitable for most general-purpose applications requiring transactions, foreign keys, and row-level locking (OLTP).
- InnoDB tables consume more disk space compared to MyISAM, and there might be slight overhead due to transactional features.
- MyISAM was historically the default storage engine in MySQL before InnoDB.
- It offers fast read operations, making it suitable for read-heavy applications such as data warehousing and reporting.
- MyISAM does not support transactions or foreign keys, which can impact data integrity and concurrency.
- Suitable for read-heavy applications where fast read operations are essential, and transactions and foreign keys are not required.
Memory (HEAP):
- The Memory storage engine (formerly known as HEAP) stores tables entirely in memory.
- It provides extremely fast read and write operations.
- Data stored in memory tables is volatile and is lost when the MySQL server restarts.
- Suitable for caching frequently accessed data or temporary storage, offering extremely fast read and write operations.
NDB Cluster (NDB):
- The NDB Cluster storage engine is designed for distributed, high-availability, and real-time applications.
- It provides synchronous replication and automatic partitioning of data across multiple nodes in a cluster.
- Suitable for distributed, high-availability, and real-time applications requiring high scalability and fault tolerance.
Archive:
- The Archive storage engine is optimized for storing and retrieving large amounts of data with minimal space requirements.
- It supports only INSERT and SELECT operations, making it suitable for storing historical data or audit logs.
- Suitable for storing large volumes of data with minimal space requirements, such as historical data or audit logs.
CSV:
- The CSV storage engine stores data in comma-separated values (CSV) format.
- It is useful for exchanging data with spreadsheet applications or for temporary storage of data that needs to be manipulated outside of MySQL.

Each storage engine has its own strengths, weaknesses, and suitability for different types of applications and workloads. The choice of storage engine depends on factors such as the nature of the application, the types of queries it will execute, and the desired level of data integrity and performance.
Be aware of storage engine compatibility when migrating databases between different MySQL versions or platforms. Some features may not be supported or may behave differently across versions.
NOTE : Always backup data before changing engine for an existing table. During the engine change, the table will be locked, which prevents any write operations (inserts, updates, deletes) from occurring on the table.
---------------------------------------------------------------------------------------------------------------
Character Set & Character Encoding
A Character Set is a collection of textual data (numbers, letters etc) where each character is mapped to a unique code called "code point". Each character set has a defined set of characters inside of it that determines the scope of characters supported by that character set.
For example, the ASCII character set includes characters like 'A', 'B', '1', '2', and punctuation marks, each with its own code point. Another example is the UTF-8 character set, which includes a much wider range of characters, including those used in languages like Chinese, Japanese, and Arabic, as well as special symbols and emojis.

Character encoding is the process of converting the codepoint of a character set into binary values. Character encoding translates characters from a character set into binary code. It takes each character's code point and converts it into a series of 0s and 1s that represent that character's binary value that can be stored in database.
Databases typically store data internally in binary format.When inserting data it often undergoes encoding i.e encoded into binary format and then stored. Whereas while retrieving the data it's decoded back to it's original format.
The character set supported by a database determines the type of textual data it can store and manipulate. When you choose a character set for your database, you're essentially defining the scope of characters that the database can handle. If you attempt to insert data that contains characters outside of the chosen character set, the database may not be able to handle it properly.

utf8mb4. This character set is commonly used for storing Unicode data and supports a wide range of characters, including those used in various languages, symbols, and emojis. Collation
Collation is a set of rules that dictate how character data is compared and sorted within the database. It defines the order in which characters are arranged when sorting data and how characters are compared when performing string operations such as searching and filtering.
Collations are often defined within the context of a specific character set. Each character set may have multiple collations associated with it, each representing different sorting and comparison rules.
For example, the UTF-8 character set can have multiple collations such as utf8_general_ci (case-insensitive) and utf8_bin (case-sensitive). Similarly, the Latin1 character set can have collations like latin1_swedish_ci and latin1_general_ci.
Below are some commonly used collations in MySQL as followed :
utf8_general_ci: This collation is for UTF-8 encoded text and provides case-insensitive sorting. It treats accented characters and letter case equivalently during sorting, making it suitable for general-purpose applications.
utf8_bin: Designed for UTF-8 encoded text, this collation offers case-sensitive sorting. It considers letter case and accents when sorting data, providing a more strict sorting order. Useful when case sensitivity is required, such as for distinguishing between uppercase and lowercase letters.
latin1_swedish_ci: Optimized for Latin1 encoded text, this collation offers case-insensitive sorting with Swedish language conventions. It follows specific sorting orders for characters like 'å', 'ä', and 'ö', making it suitable for applications with Swedish language data.
latin1_general_ci: Similar tolatin1_swedish_ci, this collation is for Latin1 encoded text and provides case-insensitive sorting. However, it follows general sorting rules rather than specific language conventions, making it suitable for general-purpose applications.
utf8mb4_general_ci: An extension ofutf8_general_ci, this collation supports the full Unicode range, including supplementary characters beyond the Basic Multilingual Plane (BMP). It offers case-insensitive sorting for UTF-8 encoded text with support for a wider range of characters.
utf8mb4_bin: Similar toutf8_bin, this collation is for UTF-8 encoded text but provides case-sensitive sorting and binary comparison. It's useful for scenarios requiring exact character matches and binary comparison, such as for binary data or sensitive string operations.
NOTE : In MySQL 8.0 the default collation for the UTF-8 character set (utf8mb4) is typically utf8mb4_0900_ai_ci. This collation is case-insensitive and accent-insensitive, providing compatibility with modern Unicode standards.
Below are some points in which different collations may differ as follows :
Case Sensitivity: Collations may be case-sensitive or case-insensitive, affecting how uppercase and lowercase letters are treated during sorting and comparisons.
- Accent Sensitivity: Some collations consider accents and diacritics when sorting and comparing characters, while others ignore them, impacting the sorting order and comparisons involving accented characters.
- Language-specific Sorting Rules: Collations may follow specific language conventions for sorting characters, resulting in different sorting orders for languages with unique linguistic requirements.
- Binary Sorting: Certain collations offer binary sorting, sorting characters based on their binary representation rather than linguistic rules, useful for exact matches or binary data.
- Performance Characteristics: Collations can vary in terms of sorting speed and memory usage, with some collations being more optimized for performance-intensive operations due to difference in collation rules.
In MySQL, each column can have its own collation, which determines the way data in that column is sorted and compared. Collations are specified at the column level and define the rules for sorting and comparing textual data within that column.
Having different collations for different columns allows for flexibility in sorting and comparing data within a table. For example, you might have a column storing names where case sensitivity is important, so you would choose a case-sensitive collation for that column. In another column storing descriptions, you might prefer case-insensitive sorting, so you would select a case-insensitive collation.
However, there are some indirect ways in which collation can affect performance :
- Choose the Right Collation: Select a collation that aligns with your application's requirements while considering performance implications. Collations with simpler rules, such as binary sorting or case-insensitive sorting without accent sensitivity, often offer better performance compared to more complex collations.
- Index Usage: Collation can influence whether indexes can be used efficiently for query execution. If the collation of a column in a WHERE clause doesn't match the collation of the index on that column, MySQL might not be able to use the index effectively, leading to slower query execution. In such cases, changing the collation to match the index could potentially improve performance.
- Avoid Unnecessary Complex Collations: Avoid using overly complex collations if they are not essential for your application. Simplifying collation rules, such as using case-insensitive sorting instead of case-sensitive sorting, can improve query performance by reducing computational overhead.
- Use Case-specific Collations: Choose collations tailored to your specific language or sorting requirements. For example, if your application primarily deals with English text, selecting a case-insensitive collation optimized for English text can enhance performance by leveraging language-specific sorting optimizations.
- Consider Storage Overhead: Some collations may incur additional storage overhead due to the need for extra metadata or sorting tables. Evaluate the trade-offs between performance and storage requirements when selecting collations, especially for large datasets or resource-constrained environments.
---------------------------------------------------------------------------------------------------------------
Database Replication
MySQL database replication, often referred to as "master-slave" replication, is a process of copying data from one MySQL database (the master) to one or more MySQL databases (the slaves). This replication process allows you to maintain multiple copies of database in sync, providing several benefits such as improved performance, scalability, fault tolerance, and data redundancy.
In a typical master-slave architecture, the master database serves as the primary source of data, and the slave databases replicate data from the master. Any changes (inserts, updates, deletes) made to the data on the master are asynchronously replicated to the slave databases.

By replicating data across multiple servers, database replication provides fault tolerance and high availability. If the primary database server fails, one of the replicas can take over, minimizing downtime and ensuring continuous access to data.
Replication allows distributing read-heavy workloads across multiple database servers. Clients can read data from any replica, reducing the load on the primary server and improving overall system performance.
Below are some common setups for database replication as followed :
Master-Slave Replication:
- One master database (write operations) replicating changes to one or more slave databases (read operations).
- Commonly used for read scaling, high availability, and disaster recovery.
Master-Master Replication:
- Multiple master databases capable of accepting write operations.
- Changes made on any master are asynchronously replicated to other master databases.
- Used for better write scalability and high availability, but requires careful conflict resolution.
Cascading Replication:
- Multiple levels of replication, where changes are propagated from one master to another master and then to slaves.
- Used for distributing data across multiple geographic regions or for hierarchical data distribution.
NOTE : In many database replication setups, read operations are shifted to slave nodes to distribute the read workload and improve overall system performance. This approach is particularly effective for read-heavy workloads. This also prevents tables from locking due to long-running SELECT queries which can prevent other operations on same table.
---------------------------------------------------------------------------------------------------------------



Comments
Post a Comment